






I ricercatori dell’Istituto Nazionale di Astrofisica Andrea De Luca (a sinistra) e Ruben Salvaterra (a destra). Crediti: A. De Luca, R. Salvaterra (Inaf)
Gli archivi di dati astronomici stanno diventando sempre più grandi e ricchi di informazioni. L’approccio tradizionale all’analisi dei dati e l’ispezione visuale delle sorgenti non sono più sufficienti per cercare oggetti peculiari o selezionare campioni di sorgenti interessanti, e il futuro di queste ricerche prevede il ricorso a metodi di analisi dati basati sull’intelligenza artificiale.
Un nuovo lavoro guidato da un team dell’Istituto nazionale di astrofisica dimostra le potenzialità di questo nuovo approccio, effettuando una caratterizzazione omogenea delle proprietà temporali del catalogo Extras (Exploring the X-ray Transient and variable Sky) che contiene oltre centomila sorgenti osservate nei raggi X con il telescopio spaziale Xmm-Newton dell’Agenzia spaziale europea (Esa). I risultati di questo studio sono stati pubblicati in un articolo sulla rivista Astronomy & Astrophysics.
«Alcuni anni fa avevamo iniziato ad analizzare la variabilità temporale di queste sorgenti – che sono tutte le sorgenti viste da Xmm-Newton – per capire meglio la loro natura e dare una caratterizzazione temporale più completa possibile», spiega Andrea De Luca, ricercatore Inaf a Milano, co-autore del nuovo articolo e coordinatore del progetto Extras. «Per ogni sorgente ci sono un centinaio di parametri che ne quantificano le caratteristiche, quindi per sfruttare in modo ancora più completo questo catalogo, abbiamo pensato di sfruttare l’intelligenza artificiale e il machine learning».
L’algoritmo scelto è del tipo machine learning “non supervisionato” – significa che il computer riesce a svolgere un compito complesso su una mole di dati enorme senza ricevere istruzioni da parte degli astronomi. In questo caso, l’intelligenza artificiale riesce a dividere le sorgenti del catalogo in gruppi, separando – in modo molto efficiente – diversi fenomeni celesti che l’occhio di un astronomo riconoscerebbe, ad esempio, come eclissi oppure brillamenti (flares), pur senza basarsi su un modello di evoluzione temporale delle sorgenti.
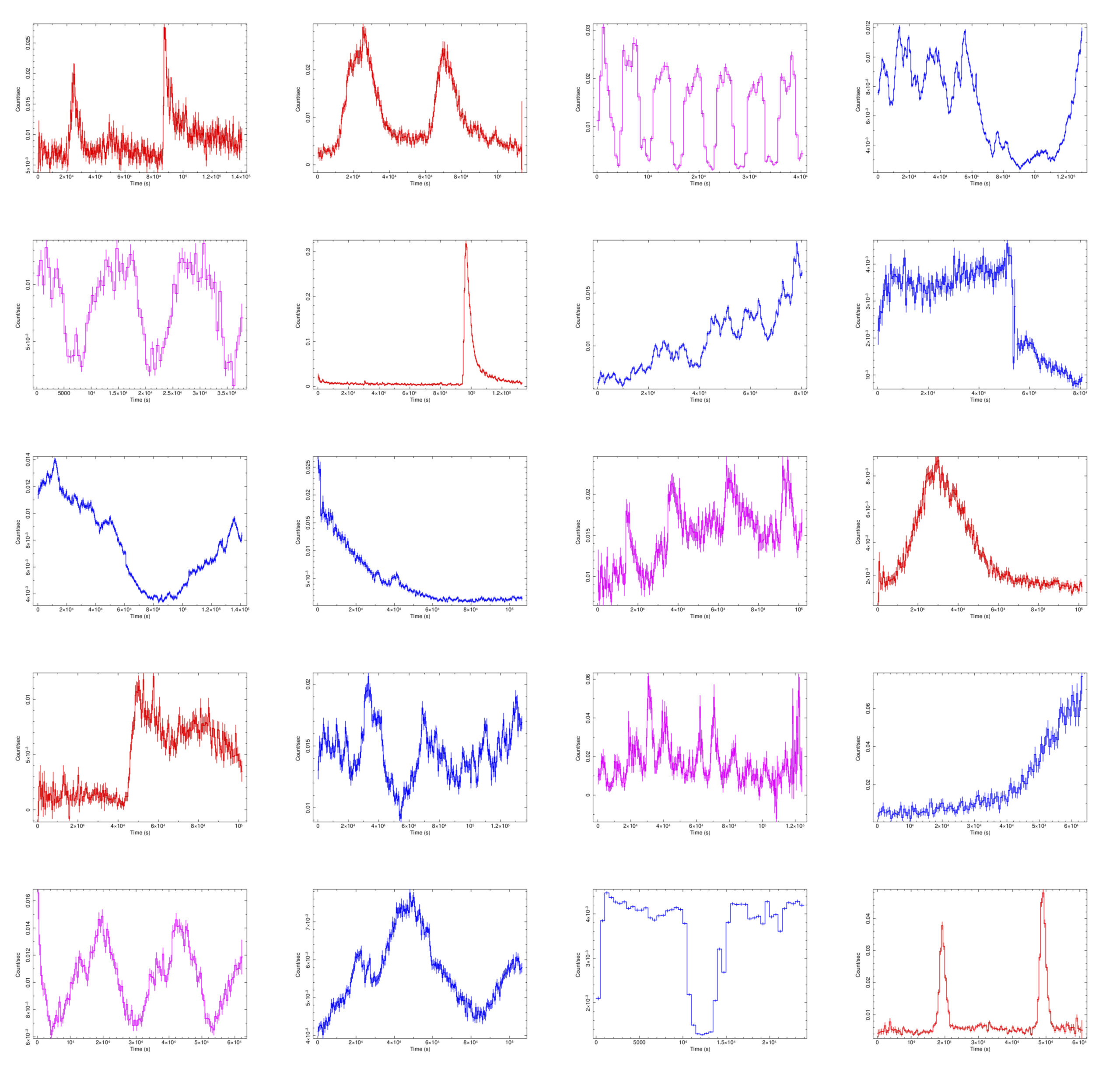
Esempi di come varia nel tempo la luminosità di 20 sorgenti del catalogo Extras, osservate in banda X con il telescopio spaziale Xmm-Newton. Le variazioni mostrate in questi grafici coprono intervalli dell’ordine di decine di ore. I colori indicano diversi tipi di variabilità temporale: sorgenti che emettono flare (rosso), sorgenti con variabilità periodica (magenta) e sorgenti con comportamento più complesso (blu). Crediti: Extras/Xmm-Newton/Esa/A. De Luca (Inaf)
Algoritmi di questo tipo si erano già dimostrati utili nell’analisi di altri dati astronomici, in particolare cataloghi più piccoli di osservazioni in banda ottica. Questa è la prima applicazione a un grande catalogo nel campo dell’astrofisica delle alte energie.
«Come in altri campi, si può utilizzare il machine learning come strumento per aiutare e velocizzare la ricerca», aggiunge Milos Kovačević, primo autore dell’articolo, che ha selezionato e implementato l’algoritmo durante un post-doc all’Inaf. «A parte l’elevato volume di dati astronomici, il machine learning non supervisionato può riconoscere pattern nei dati che gli esseri umani non sarebbero in grado di vedere con algoritmi statistici tradizionali. Questo potrebbe portare a nuove scoperte astrofisiche».
L’applicazione di algoritmi di intelligenza artificiale offre un aiuto fondamentale per risolvere i problemi di classificazione in astrofisica, anche al di là di una semplice ricerca di sorgenti cosmiche particolarmente interessanti. Come dimostra questo lavoro, che applica un algoritmo già esistente e usato in altri ambiti per studiare in modo innovativo un set di dati enorme, un simile approccio può essere utile per isolare gruppi di sorgenti con proprietà particolari, oppure per individuare sorgenti apparentemente “strane” o ancora per selezionare fenomeni particolarmente interessanti e imprevedibili come i flare in maniera automatica.
«Visualizzare 150 dimensioni è difficile per la mente umana ma il computer lo fa tranquillamente: semplifica il problema e lo trasforma in una mappa più semplice», commenta Ruben Salvaterra, ricercatore Inaf a Milano e co-autore dell’articolo. «È interessante esplorare le scelte fatte dall’algoritmo. Alcune non sono affatto banali per l’astronomo: raggruppa sorgenti diverse in gruppi simili, per esempio, oppure sorgenti simili in gruppi diversi. Adesso tocca a noi analizzare questi gruppi per comprendere la ragione astrofisica dietro a queste selezioni».
Per saperne di più:
- Leggi su Astronomy & Astrophysics l’articolo “Exploring X-ray variability with unsupervised machine learning I. Self-organizing maps applied to XMM-Newton data”, di M. Kovačević, M. Pasquato, M. Marelli, A. De Luca, R. Salvaterra e A. Belfiore