





A breve uscirà sulla rivista Astronomy & Astrophysics uno studio relativo a un nuovo metodo basato sul transfer learning che si sta rivelando molto utile per trovare anomalie nelle serie temporali astronomiche. Il transfer learning (o apprendimento per trasferimento) è una tecnica di apprendimento automatico in cui un modello addestrato su un compito specifico viene riutilizzato come punto di partenza per un altro compito. Questo approccio è particolarmente utile quando si hanno pochi dati per il nuovo compito, poiché sfrutta la conoscenza acquisita durante l’addestramento su un set di dati più ampio e diverso. Per capire come lavora il nuovo metodo ideato e realizzato anche grazie a ricercatori dell’Inaf, Media Inaf ne ha parlato con il primo autore, Stefano Cavuoti dell’Inaf di Napoli, ricercatore ed esperto di intelligenza artificiale, e con la coautrice Demetra De Cicco, ricercatrice dell’Università di Napoli Federico II.

Demetra De Cicco, ricercatrice dell’Università degli Studi di Napoli Federico II.
Nel vostro articolo presentate un nuovo metodo per l’identificazione di epoche problematiche nelle serie temporali astronomiche. Di quale serie temporali si tratta e cosa si intende per epoche problematiche?
[De Cicco] «Si tratta di osservazioni ripetute con un’elevata cadenza (circa ogni tre giorni, anche se divise in stagioni temporalmente separate) della stessa regione di cielo; dunque, le stesse sorgenti (o oggetti) vengono osservate ripetutamente, in tempi diversi. In totale possediamo oltre ventimila sorgenti con una cinquantina di osservazioni ciascuna, che diverranno di più non appena finiremo la riduzione dei dati. Nei dati astronomici possono esserci problemi, a volte relativi alla procedura che passa dal dato grezzo al dato anche detto ridotto su cui normalmente si lavora, ma per lo più dovuti a qualcosa che accade visivamente in prossimità dell’oggetto. Ad esempio, per le osservazioni da terra un tipico problema è il transito di un satellite o di qualche altro corpo celeste, che si manifesta con una traccia lineare nelle immagini. Questo transito nei casi peggiori può completamente coprire l’oggetto di interesse in una delle osservazioni, ma anche quando è solo relativamente vicino può andare a influenzare il calcolo del background o la fotometria di apertura, alterando la misura della magnitudine e quindi tutti i valori statistici che possiamo estrarre dalla curva di luce. In alcuni casi questo effetto è poco rilevante ma in alcuni casi può essere piuttosto evidente e falsare parzialmente l’analisi delle curve di luce stesse».
In che cosa consiste questo nuovo metodo che avete sviluppato?
[Cavuoti] «Il nostro metodo utilizza una metodologia dell’intelligenza artificiale chiamata transfer learning ovvero la capacità di trasferire parte di ciò che hanno imparato da un ambito a un altro. Vogliamo fare questa cosa perché come spesso si dice gli algoritmi di intelligenza artificiale sono buoni tanto quanto i dati con cui si vanno ad addestrare, frase che è in parte un’esagerazione ma non del tutto. Spesso in astrofisica uno dei problemi che si hanno applicando questo tipo di metodologie è proprio avere un insieme di dati abbastanza ampio e abbastanza ben definito da poterli applicare. Nella maggioranza dei casi abbiamo o insiemi di dati molto grandi ma con incertezze significative su “chi è cosa” oppure insiemi molto ben conosciuti ma di dimensioni relativamente piccole (per gli standard di questi algoritmi). La terza strada sono ovviamente le simulazioni che però pure sono soggette a criticità quando poi ci si confronta con il dato reale. In questo caso la dimensione della singola serie temporale è abbastanza ridotta, al di sotto del centinaio di epoche e rende problematico un addestramento specifico».

Stefano Cavuoti è un ricercatore dell’Osservatorio Astronomico di Capodimonte, esperto di Intelligenza Artificiale. Nel 2016 ha ricevuto il premio “Outstanding Publication in Astrostatistics PostDoc Award” dell’International Astrostatistics Association. È uno dei builder della missione Euclid. Crediti: S. Cavuoti
E come avete fatto?
[Cavuoti] «Abbiamo considerato un dataset molto noto e molto utilizzato nell’ambito dell’intelligenza artificiale: ImageNet. Si tratta di un insieme estremamente eterogeneo che contiene milioni di immagini suddivise in migliaia di categorie che vanno da cani, gatti, biciclette e auto. Su questo dataset si sono cimentati, e si cimentano ogni anno, alcuni tra i migliori metodi per la classificazione di immagini sviluppati nell’ambito dell’intelligenza artificiale. Noi siamo andati a considerare quello che è uno dei metodi che ha funzionato meglio EfficientNet-b0 e ne abbiamo estratto un pezzo».
Perché solo un pezzo? In che senso?
[Cavuoti] «Semplificando al massimo, praticamente tutti i metodi di intelligenza artificiale che lavorano sulla classificazione delle immagini sono composti da due parti: la prima, tramite la convoluzione con dei filtri (o Kernel) e tramite degli strati di compressione, estrae quelle che si chiamano in gergo feature e che sono dei parametri che rappresentano l’immagine. La seconda è il classificatore vero e proprio che lavora sulle feature estratte e può essere ad esempio una rete neurale. L’algoritmo da un lato deve imparare quali sono le feature più efficienti per effettuare il compito che gli è stato affidato (nel caso di ImageNet, classificare immagini), ossia deve imparare quali feature sono in grado di rappresentare in maniera quanto più efficace possibile l’immagine di partenza. Dall’altro, deve ottimizzare il processo di apprendimento vero e proprio del classificatore. Quello che andiamo a fare noi è eliminare la seconda parte dal sistema che ha imparato a classificare le immagini, lasciando solo quella di estrazione delle feature, sperando che la varietà delle immagini sia tale da permettere a queste feature di essere così generali da essere adeguate per descrivere anche le immagini astrofisiche».
Lo avete già testato su dati astronomici?
[De Cicco] «Sì, lo abbiamo utilizzato su un dataset di immagini prese da Vst (Vlt Survey Telescope) che sono per noi particolarmente interessanti perché sono uno dei pochi dataset che sarà confrontabile con i dati survey Lsst del Vera C. Rubin Observatory».
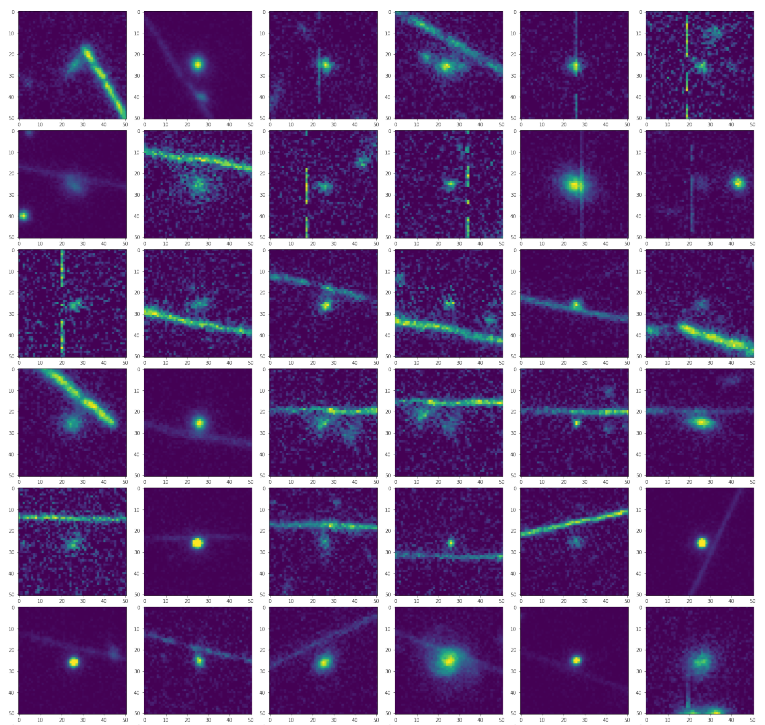
Alcune immagini problematiche identificate dal metodo presentato in questo articolo, che verrà illustrato anche al simposio Bridging Knowledge: Artificial Intelligence organizzato da Agenzia spaziale italiana questa settimana. Crediti: Cavuoti et al. 2024
Quali sono i vantaggi nella sua applicazione?
[Cavuoti] «Nel momento in cui i dati astronomici stanno aumentando sempre più, e in particolare le serie temporali che arriveranno da Lsst, non è ovviamente possibile analizzare le curve di luce una per una come magari si faceva in passato, attualmente nella maggior parte dei casi si fanno dei tagli – come ad esempio il sigma clip – che rimuovono alcuni valori estremi ma non riescono a individuare tutte le possibili problematiche che possiamo andare a trovare nelle immagini. Il nostro metodo, non cercando semplicemente un picco (o una valle) nella curva di luce, è in grado di identificare alcune di queste epoche che erano sfuggite, come ad esempio quelle che si possono vedere nella figura accanto».
Esistono limitazioni alla sua applicazione?
[De Cicco] «Sì, ci siamo resi conto che anche il nostro metodo da solo trascurava alcune epoche che invece il sigma clip riusciva a individuare (sebbene va detto che entrambi i metodi riescono a identificare agilmente tutte le epoche più catastrofiche). Abbiamo quindi deciso di applicarli in sequenza e, almeno nel dataset che abbiamo utilizzato per i test, dopo una lunga ispezione manuale non abbiamo trovato alcuna epoca problematica ulteriore da eliminare».
Per saperne di più:
- Leggi su arXiv il preprint dell’articolo in uscita su Astronomy & Astrophysics “Identification of problematic epochs in Astronomical Time Series through Transfer Learning” di Stefano Cavuoti, Demetra De Cicco, Lars Doorenbos, Massimo Brescia, Olena Torbaniuk, , Giuseppe Longo e Maurizio Paolillo